If I Can Make Spreadsheet Tools is It Easy to Learn Programming
DATA SCIENCE IN THE REAL WORLD
Is The Age of The Spreadsheet Over?
Why modern data analysis tools still struggle to compete.

People are saying we should ditch spreadsheet applications like Microsoft Excel and use more advanced tools for data analysis. Open-source programming languages such as Python are accessible to the every-day user and easier to learn than previous languages. Tools like the Jupyter Notebook are revolutionizing the way we write and use code. There's even a post on Microsoft's user website asking for comments on the idea of 'Python as an Excel scripting language' (it got 6300 votes and many comments).
In this article, I try to elucidate the essential features that make spreadsheets so popular and so effective as general-purpose data analysis tools for so many users. For me it boils down to three attributes:
- Spreadsheets are data-centric
- Spreadsheets are visually intuitive — like a sheet of paper
- Spreadsheets manage the computation graph for you
To illustrate these ideas, I compare and contrast the spreadsheet approach with using a programming language to accomplish a simple task.
Finally, I outline the drawbacks of current spreadsheet applications and modern programming tools such as Jupyter notebooks, and speculate on what might be coming to bridge the gap between these two paradigms.
I use Python on a daily basis to do data analysis for clients. Before that I used Excel for over 20 years. Now that I am proficient in Python and its data science libraries, I find I'm more productive and able to implement much more powerful analysis techniques with more confidence than I ever was with spreadsheets. I really only use Excel to share data and final results with clients.
So I found myself wondering "is the spreadsheet dead?" and if not, "why not?"
My first response was to condemn spreadsheets to the trash can of computing history — I spent too many hours wrestling with ridiculously-complicated formulas, tracing broken cell references or trying to recover corrupt files. However, once I began to think more deeply about the essence of the spreadsheet, I began to realize that it has inherent features that programming languages lack.
Spreadsheets are Data-Centric
Spreadsheets show us the data — not the calculations behind them.
Let's take a very simple example. Something that any of us might need to do. Imagine we just got back from a road trip and we need to figure out who owes who and how much.
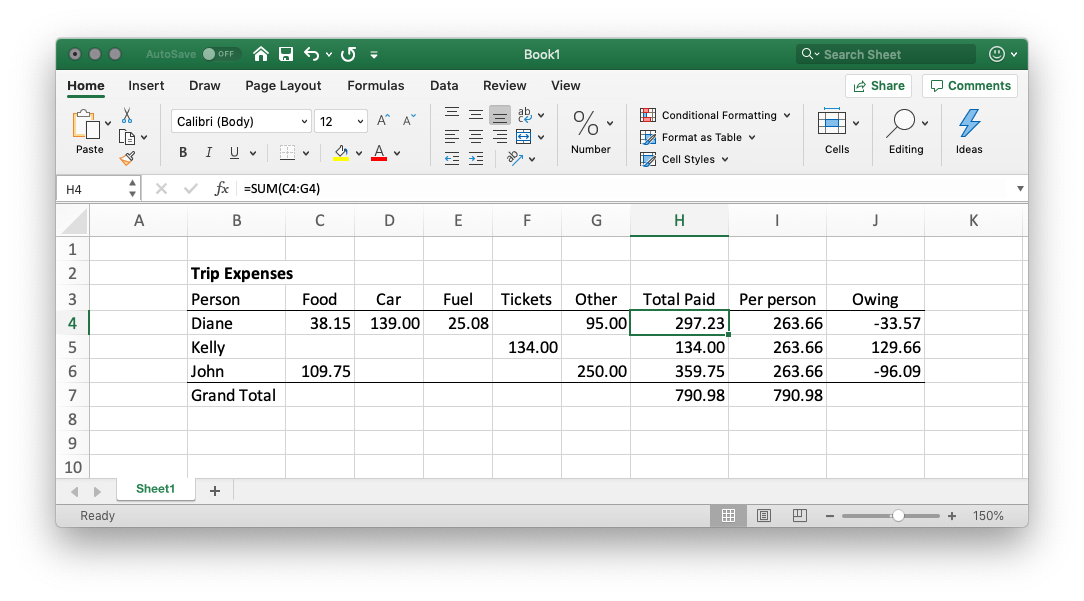
This example is so intuitive it doesn't need an explanation. When we are the originators of the data as well as the final consumers, we already understand the purpose of the analysis and usually we can guess how the calculations were made just by looking at the data and the results. In this case, you could say "the data speaks for itself."
Another feature I like about Excel is you can select multiple cells with the mouse and see common statistics such as the sum and the average.
Yet no formula is visible — we have to click on the cells to see the calculations behind them. No variable name was declared. We simply placed each data point in a different cell in an arrangement that made sense to us, and then connected the cells with calculations and cell references. The computation is completely obscured from view. I think this is one reason why spreadsheets are so useful and so popular; we know our data, we know what it represents, and we like to see it.
In contrast, most of us don't like staring at computer code. Programming languages are text-based and linear. Here's the equivalent trip expense calculation in Python.
import pandas as pd # Trip expenses
data = {
'Food': [38.15, 0, 109.75],
'Car': [139, 0, 0],
'Fuel': [25.08, 0, 0],
'Tickets': [0, 134, 0],
'Other': [95, 0, 250]
}
index = ['Diane', 'Kelly', 'John']
df = pd.DataFrame(data, index=index) # Calculate amount owing
df['Total Paid'] = df.sum(axis=1)
average_cost = df['Total Paid'].mean()
df['Amounts Owing'] = average_cost - df['Total Paid']
print(df['Amounts Owing'])
This produces:
Diane -33.57
Kelly 129.66
John -96.09
Name: Amounts Owing, dtype: float64 The code makes the computational process and the calculation method explicit but from a data perspective it's more opaque. We use labels to refer to the data but the data is not actually visible until we print it.
What values do the intermediate variables contain? To see that you need an interactive programming environment. For example, Python has an interpreter that allows you to inspect variables and execute small pieces of code one-at-a-time.
If you had just run the script above, you could use the interpreter to do some analysis on the results.
>>> df['Total Paid'].idxmax()
'John'
>>> df.loc['John']
Food 109.75
Car 0.00
Fuel 0.00
Tickets 0.00
Other 250.00
Total Paid 359.75
Owing -96.09
Name: John, dtype: float64
>>> Modern programming languages have made the data more accessible by providing interactive environments in which you can explore and visualize it.
Programming Languages are Object-Oriented
If you know something about programming, you can easily decipher what the code does. Each data object is assigned a name and has a defined type or structure. Programming languages have a large array of object types and methods and allow external packages to be imported to provide additional capabilities.
In the example code above, I used an object called a dataframe that is specially-designed for handling data-computations in two dimensions.

The variety of 'fit-for-purpose' object structures is what makes computer code robust, powerful and computationally efficient.
To overcome some of the limitations of earlier spreadsheets with only rows and columns, Microsoft added tables and other data structures to Excel to make it easier to do more sophisticated data analyses — similar to data structures from computer languages.
Here's the same spreadsheet from above but using the built-in Table format and structured referencing in Excel.
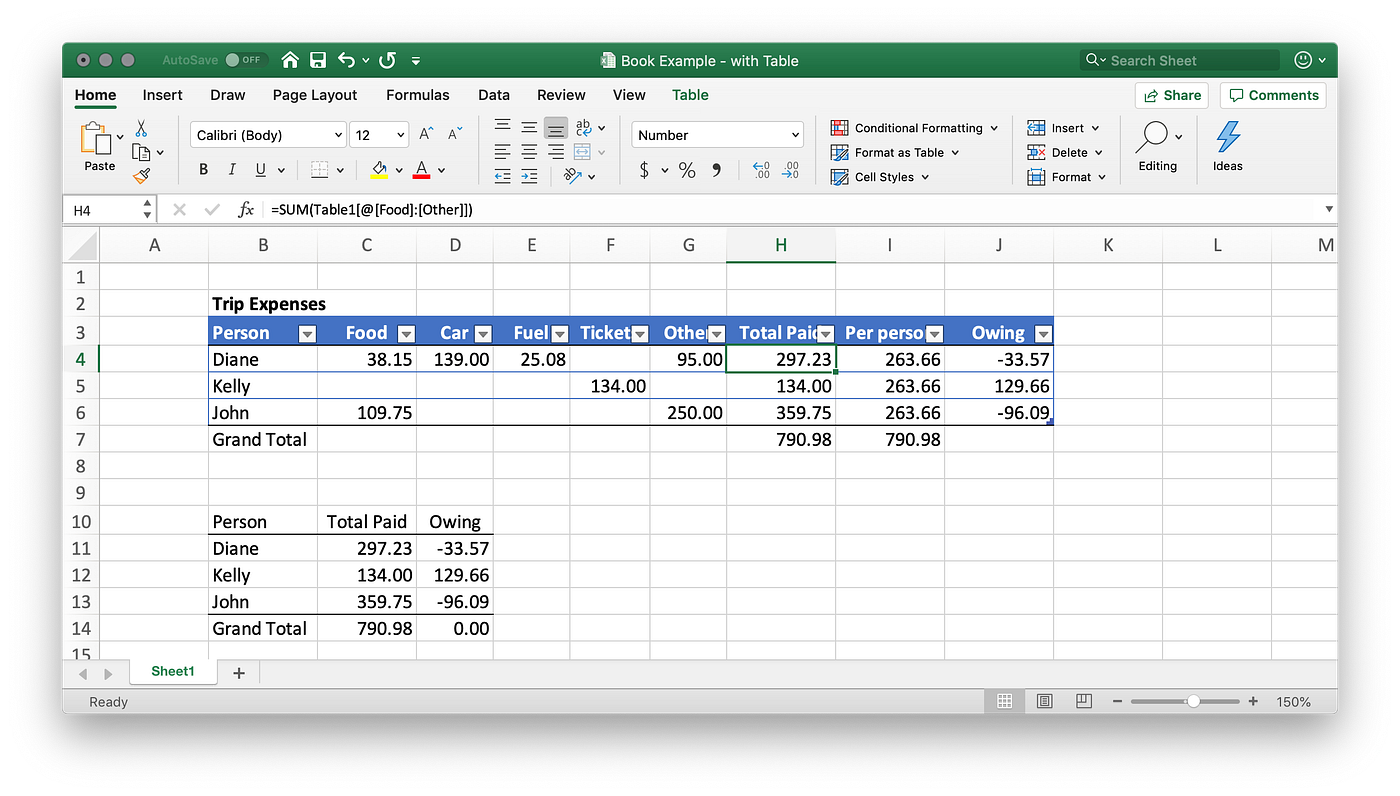
The table object has a special syntax for referencing its elements. Instead of
=SUM(C4:G4) we can now write:
=SUM(Table1[@[Food]:[Other]]) This is more intuitive and less likely to break if we make changes to the table (the '@' symbol means 'from the current row').
The equivalent in Python would be:
df.loc['Diane', 'Food':'Other'].sum() Spreadsheets are Like Sheets of Paper
One reason I think we love the spreadsheet is its resemblance to good, old paper. Writing on paper affords us control and predictability. Things are always where you left them. An old friend of mine refers to paper-based notes half-jokingly as his "persistent, flexible, storage system".
Even though we hardly use paper for numerical work these days, it has a certain intuitive appeal. I think that's because we see the world in 2-dimensions (before translating the image to 3-dimensions). It's easy to see where everything is on a flat surface laid out in front of you. Even if the area is too big to view at once, we remember where we put things because we intuitively build a 2-dimensional map of where everything is located. (The tabs on an MS workbook offer another dimension but it's really just a collection of labelled spreadsheets.)
Programmers developing user applications talk about the 'GUI' or graphical user interface. Everything that is designed to be used by humans needs a user interface. Spreadsheet apps are no exception. In fact, the spreadsheet really is a GUI. The uniform grid of cells with standardized functionality, is both a GUI and at the same time a construction system in the same way that Lego is.
When you first start on your spreadsheet, it looks fairly plain—just like a blank sheet of paper. But once you've learned how to add data and formulas, reference other cells and format them, you can use this incredibly versatile construction system to create an unimaginably vast array of different applications. The final product, a spreadsheet designed for some specific purpose, may also be a GUI to the end user. Therein lurks a hazard, of course, but I suspect that in the vast majority of cases, spreadsheets are used by the same people that created them. The developer is the user. So it makes sense that the development environment is the user interface.
A spreadsheet unleashes your creativity and gives you the freedom to build something according to our own vision. This is one of the reasons that making spreadsheets can be so enjoyable. It's both a computation platform and a user-interface, whether it's a simple data-entry form, a nicely-formatted report, or a beautiful chart.
In contrast, computer code looks monotone — you have to read the variable names and navigate a text-based code. Unlike a spreadsheet, code script is one-dimensional — a linear layout. You specify the precise order in which you want each command to be executed. The extent to which you can personalize code visually is limited by the syntax.
Dataflow Programming
Although you might not have thought about it in this way, Excel constructs a computation graph 'behind-the-scenes' so that it can execute the calculations in the correct order (I'm not exactly sure how but I assume that it uses some kind of directed graph). That graph and the process of creating it is handled automatically and obscured from you as the user. Your job is only to define the data and the dependencies between them.
What is a computation graph? A computation graph is a network diagram that describes the functional relationships between the input data and the outputs. They are used in machine learning applications where many complex computations are chained together in series. Here's what the computational graph for the Trip Expense calculation might look like. Each box is a data item and the arrows represent calculations.
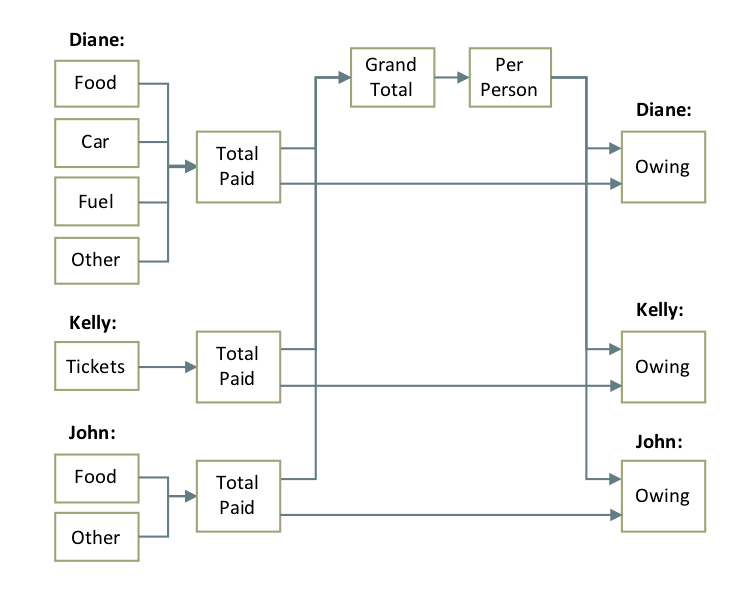
The computation graph is not always obvious when you look at a spreadsheet but if you lay out your data logically and label it well, it should be easy to imagine it. The formulas menu in Excel has some nice tools to help make the graph more visible by drawing arrows to show the dependencies between cells but I don't find it that useful for more complex graphs.
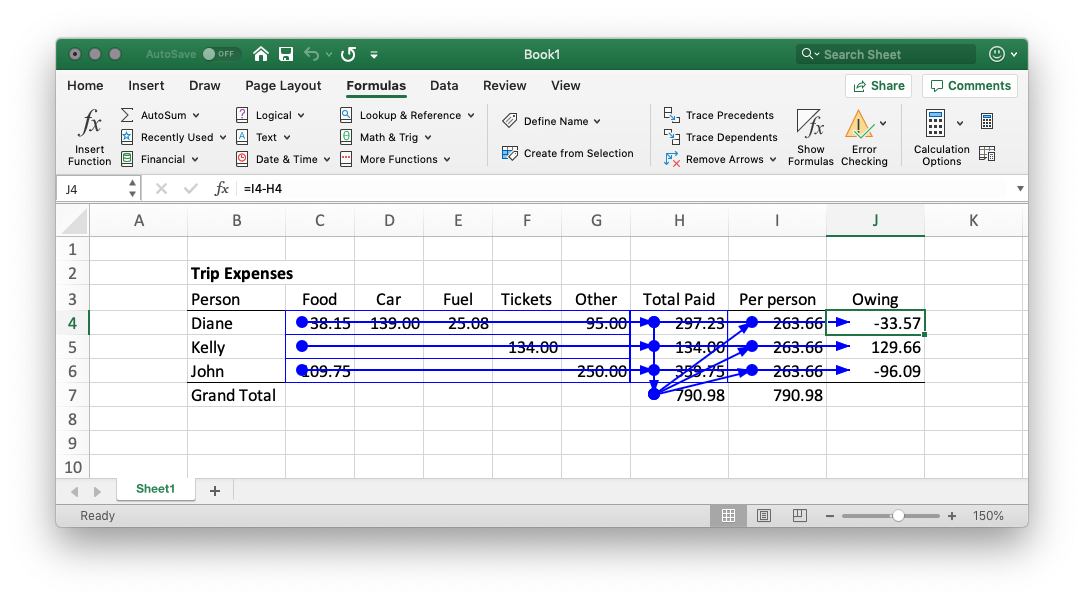
Dataflow programming is completely different to the more common sequential or procedural programming paradigms. As data analysts, I think we find it easier to think about computation as a graph or data flow model than to think about one long sequence of computation steps. This is where Excel really does excel!
When we're building a spreadsheet, we probably have some idea in our head about the computation graph we want but Excel lets us do it in a very flexible and fluid way. We don't need to start at the beginning and we can easily disconnect and join different parts of the graph later (until you create a circular reference of course, which I'm sure we've all done once or twice).
Perhaps surprisingly, there is no built-in tool to automatically handle the computation graph when we are writing computer code. It's up to you to know the order in which calculations need to happen and if you get it wrong there won't be any warning.
For example, say we got one of the expenses wrong and we need to change it. Here's what we might do.
>>> df.loc['John', 'Other'] = 25 # Correct value
>>> df
Food Car Fuel Tickets Other Total Paid Amounts Owing
Diane 38.15 139 25.08 0 95 297.23 -33.57
Kelly 0.00 0 0.00 134 0 134.00 129.66
John 109.75 0 0.00 0 25 359.75 -96.09 The correction was made to one data item but the rest of the values in the dataframe were not recalculated (as they would be automatically in a spreadsheet).
Application developers would never make this mistake of course — they carefully write the code in the correct sequence and hand-code special checks to make sure that any change to the input data automatically triggers recalculation of all variables that depend on it.
From my experience, this means that when you write code for data analysis, you need to think very carefully about the computation graph right from the start and plan and organize your code accordingly. When you write a program you are essentially determining the computation graph by the order in which the statements are written. Unless you are very good at object-oriented programming, it can be a lot of work to change the objects and relationships later if you get them wrong. We're not all professional programmers so why can't the computer do it for us? There are a few tools that could help such as d6tflow and this interesting Python package but these are specialized tools and not used that often.
Spreadsheets Don't Scale
It's hard to dynamically change the size and dimensions of data sets in Excel. You have to insert or delete rows and columns by hand. The great advantage of programming approaches is that once you've automated your analysis it's easy to scale it up and make it configurable for a variety of different-sized tasks.
Although it might take more effort and time to debug, once you have a working computer program, it tends to be much more robust (less prone to human error), is probably more efficient, and is scalable to much larger data sets than Excel is capable of processing.
Also, there are a range of tools and web-based services available that allow you to borrow and share code, collaborate and manage changes and version updates.
The Best of Both Worlds
The best of both worlds would be an interactive environment where we can create workflows and see our data in an appealing and intuitive visual format. At the same time, we want powerful data structures bound together by computational operations in a robust computation graph. As far as I know, we're not there yet although there are some interesting developments and things are moving fast.
Firstly, open-source tools such as the Jupyter Notebook have really made programming more friendly for those of us who are not professional software developers. The process of code writing and execution is not as disconnected as it used to be so now we can step through code, inspect the values of variables, and experiment with it (debugging) all in the same view. The screenshot below shows how you can view data in a Jupyter notebook right next to the code as you are editing it.
But what about the computation graph? Sadly, the Jupyter notebook doesn't provide a way to visualize the inter-connections between data objects or control their dependencies. In fact, there are quite a few problems with Jupyter notebooks once you start executing code in a non-linear way as the notebook lets you.
Perhaps the most promising direction is the recent development of business intelligence (BI) applications that offer a visual, point-and-click approach to data processing with a robust data workflow combined with powerful data analysis and visualization capabilities.
There are too many to mention and I only have limited experience with a few (e.g. Tableau, TIBCO Spotfire, Microsoft Power BI) but they all have a comprehensive suite of capabilities that spans the entire data flow pipeline from acquisition to reporting and collaboration. Many also have powerful machine learning capabilities built in.
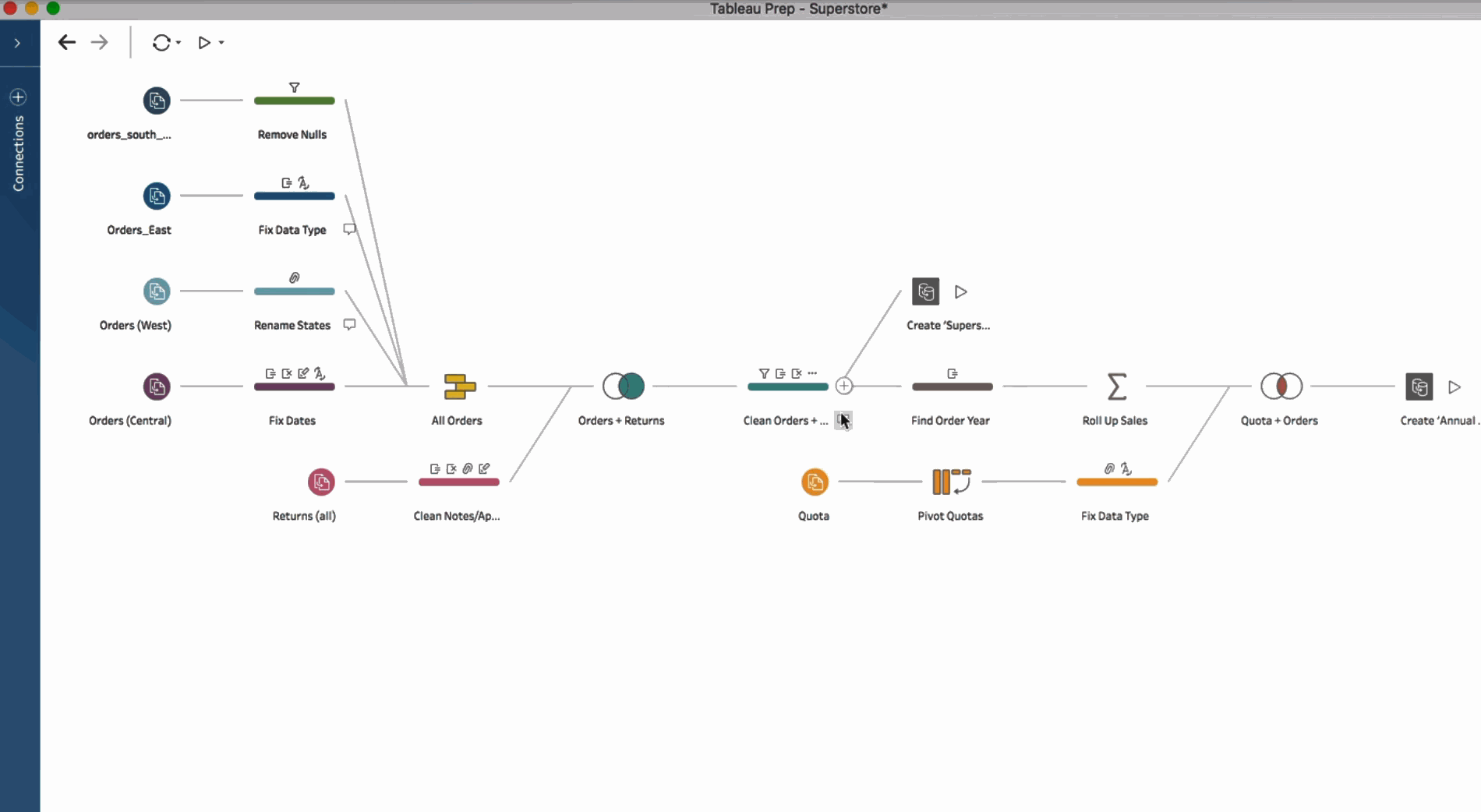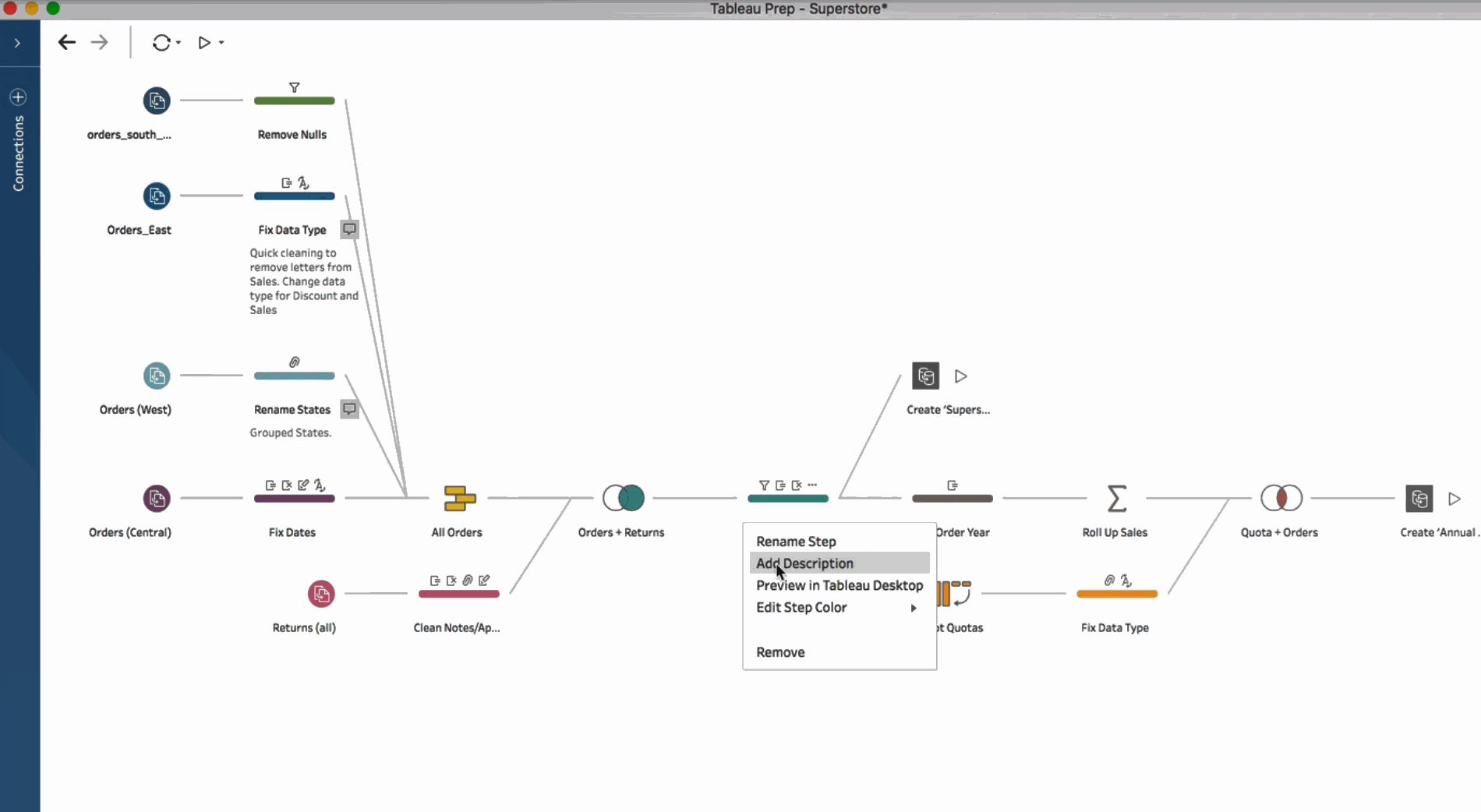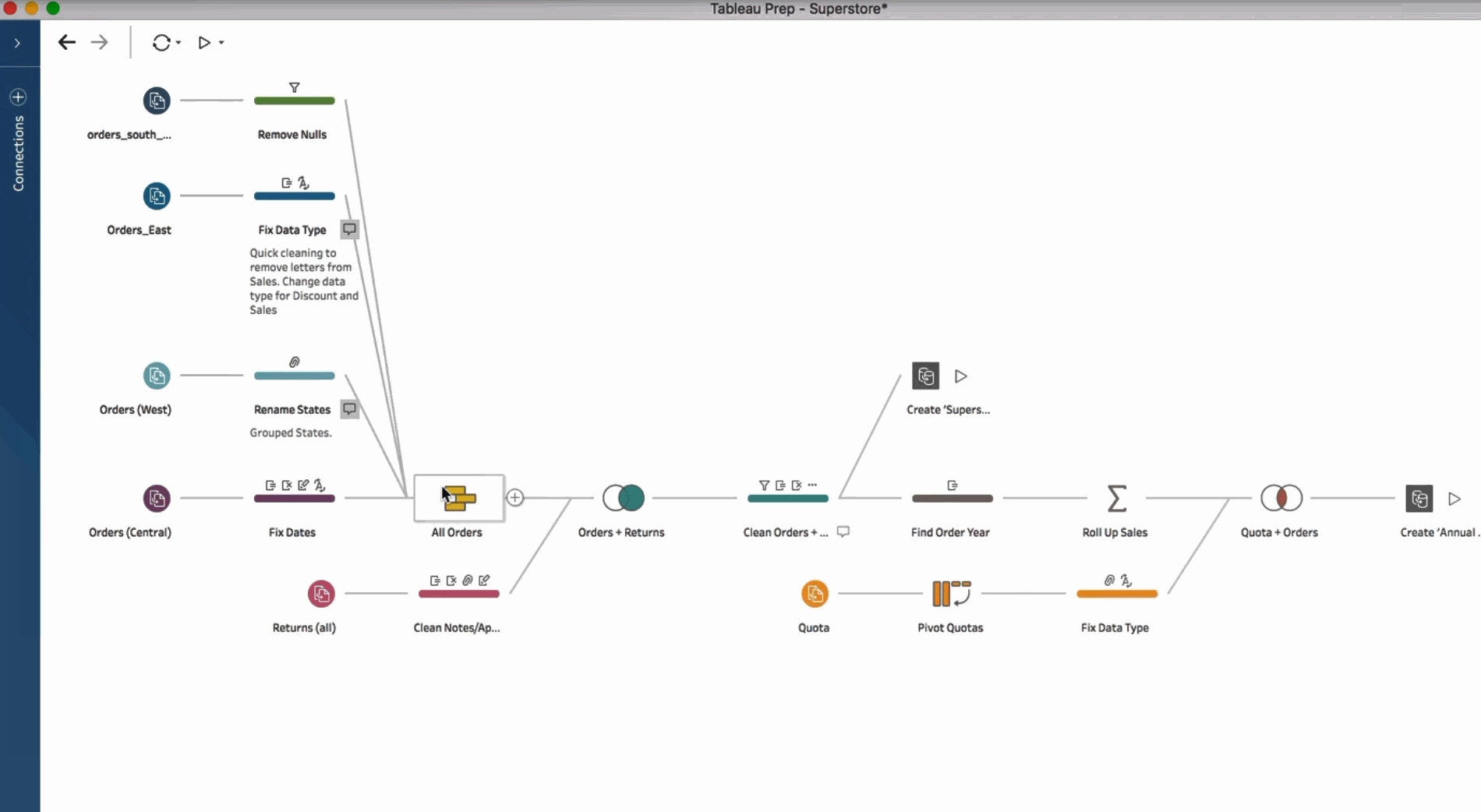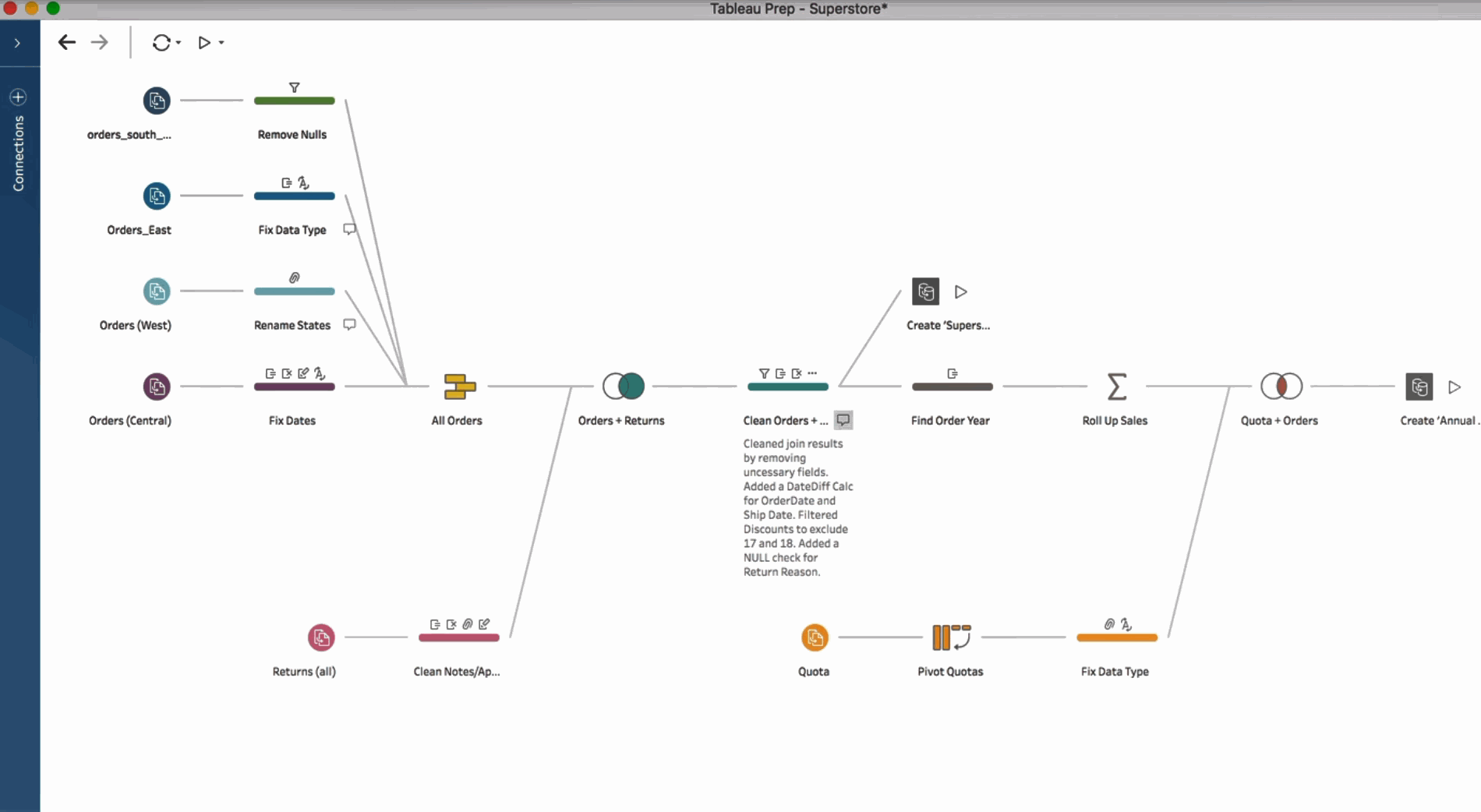
Some of these tools have now integrated high-level programming languages into their products. For example, TIBCO Spotfire comes with a built-in Python environment allowing users to add their own custom Python code. Tableau, has its own unique calculation language, similar to Excel formulas.
Looker, another popular platform, justify their decision to create a new language called LookML by arguing that existing languages were not ready and claiming that theirs is easier to learn. I think this is a mistake. Learning any new programming language is a big investment which only pays off if the language is widely used and stands the test of time. Languages such as Python, R, and Java will be around for the foreseeable future and they are probably the best languages for high-level data analysis and machine learning right now (I consider MATLAB a runner-up and it is not open-source and therefore less readily available).
What I feel these powerful BI applications lack is the simple, intuitive feel of the spreadsheet and the creative freedom it affords. Before you can work with complex, built-in capabilities, you need to have a good connection to your data and a clear, transparent working environment that you feel control over, not overwhelmed by.
Conclusion
In general, I would say that spreadsheets are perfect for people doing standard data analysis tasks and those who don't have time to learn how to code. They let you quickly explore your data and produce some immediate results without having to think too much about it.
Programming languages like Python are powerful and can handle larger volumes of data more reliably than a spreadsheet. If you need to implement a robust, efficient data processing pipeline that is going to be used more than once and has to be relied on by other people, then Python (or some other high-level programming language such as C#, R, Java, or MATLAB) is probably the way to go. But there's a big learning curve if you haven't programmed before.
Finally, commercial BI tools (assuming you have access to one) could be the solution to bridge the gap between the spreadsheet and the hand-coded computer program. But I haven't seen one yet that has both the intuitive appeal of the spreadsheet and the ability to use powerful high-level programming languages like Python.
I think we still need to figure out what that perfect working environment is. We want a solution that achieves the following:
- As intuitive as writing on a piece of paper
- Provides a transparent interface to the data
- Makes the data structure visible and manages the computation graph
- Automatically scales to accommodate different-sized datasets
- Allows customized functionality to be added using industry standard data analysis tools and programming languages.
Until we have this, I don't think the age of the spreadsheet is anywhere near over.
Getting Started
If some of the concepts in this article are new to you, check out these tutorials and learning resources.
- 3-minute video tutorial on using structured table references in Excel https://exceljet.net/lessons/introduction-to-structured-references
- 3-minute video explaining what a computation graph is https://www.youtube.com/watch?v=hCP1vGoCdYU
- Free introductory book on Python programming for complete beginners https://greenteapress.com/wp/think-python-2e/
- A 10-minute introduction to the Pandas Python library https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
- Comprehensive book on data analysis in Python available online https://jakevdp.github.io/PythonDataScienceHandbook/
doderyrunduarsted.blogspot.com
Source: https://towardsdatascience.com/have-spreadsheets-got-a-future-9b7ad23648b8
0 Response to "If I Can Make Spreadsheet Tools is It Easy to Learn Programming"
Post a Comment